Real-Time Feature Engineering for Machine Learning with DocumentDB
Ever wanted to take advantage of your data stored in DocumentDB for machine learning solutions? This blog post demonstrates how to get started with event modeling, featurizing, and maintaining feature data for machine learning applications in Azure DocumentDB.
Properties of RFM features:
- RFM feature values can be calculated using basic database operations.
- Raw values can be updated online as new events arrive.
- RFM features are valuable in machine learning models.
Because insights drawn from raw data become less useful over time, being able to calculate RFM features in near real-time to aid in decision-making is important [1]. Thus, a general solution that enables one to send event logs and automatically featurize them in near real-time so the RFM features can be employed in a variety of problems is ideal.
Where does DocumentDB fit in?
Azure DocumentDB is a blazing fast, planet-scale NoSQL database service for highly available, globally distributed apps that scales seamlessly with guaranteed low latency and high throughput. Its language integrated, transactional execution of JavaScript permits developers to write stored procedures, triggers, and user defined functions (UDFs) natively in JavaScript.
Thanks to these capabilities, DocumentDB is able to meet the aforementioned time constraints and fill in the missing piece between gathering event logs and arriving at a dataset composed of RFM features in a format suitable for training a machine learning model that accurately segments customers. Because we implemented the featurization logic and probabilistic data structures used to aid the calculation of the RFM features with JavaScript stored procedures, this logic is shipped and executed directly on the database storage partitions. The rest of this post will demonstrate how to get started with event modeling and maintaining feature data in DocumentDB for a churn prediction scenario.The end-to-end code sample of how to upload and featurize a list of documents to DocumentDB and update RFM feature metadata is hosted on our GitHub.
Scenario
The first scenario we chose to tackle to begin our dive into the machine learning and event modeling space is the problem from the 2015 KDD Cup, an annual Data Mining and Knowledge Discovery competition. The goal of the competition was to predict whether a student will drop out of a course based on his or her prior activities on XuetangX, one of the largest massive open course (MOOC) platforms in China.
The dataset is structured as follows:
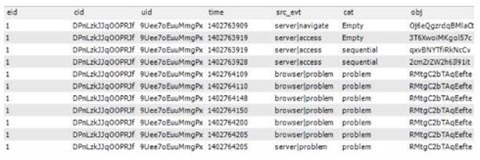
Each event details an action a student completed. Examples include watching a video or answering a particular question. All events consist of a timestamp, a course ID (cid), student ID (uid), and enrollment ID (eid) which is unique for each course-student pair.
Approach
Modeling Event Logs
The first step was to determine how to model the event logs as documents in DocumentDB. We considered two main approaches. In the first approach, we used the combination of as the primary key for each document. An example primary key with this strategy is <”eid”, 1, “cat”>. This means that we created a separate document for each feature we wanted to keep track of when the student enrollment id is 1. In the case of a large number of features, this can result in a multitude of documents to insert. We took a bulk approach in the second iteration, using instead as the primary key. An example primary key with this strategy is <”eid”, 1>. In this approach, we used a single document to keep track of all the feature data when the student enrollment id is 1.
The first approach minimizes the number of conflicts during insertion because there is the additional feature name attribute, making the primary key more unique. The resulting throughput is not optimal, however, in the case of a large number of features because an additional document needs to be inserted for each feature. The second approach maximizes throughput by featurizing and inserting event logs in a bulk manner, increasing the probability of conflicts. For this blog post, we chose to walk through the first approach, which provides for simpler code and fewer conflits.
Create the stored procedure responsible for updating the RFM feature metadata.
private static async Task CreateSproc()
{
string scriptFileName = @”updateFeature.js”;
string scriptName = “updateFeature”;
string scriptId = Path.GetFileNameWithoutExtension(scriptFileName);
var client = new DocumentClient(new Uri(Endpoint), AuthKey);
Uri collectionLink = UriFactory.CreateDocumentCollectionUri(DbName, CollectionName);
var sproc = new StoredProcedure
{
Id = scriptId,
Body = File.ReadAllText(scriptFileName)
};
Uri sprocUri = UriFactory.CreateStoredProcedureUri(DbName, CollectionName, scriptName);
bool needToCreate = false;
try
{
await client.ReadStoredProcedureAsync(sprocUri);
}
catch (DocumentClientException de)
{
if (de.StatusCode != HttpStatusCode.NotFound)
{
throw;
}
else
{
needToCreate = true;
}
}
if (needToCreate)
{
await client.CreateStoredProcedureAsync(collectionLink, sproc);
}
}
Step 2
Featurize each event. In this example, each student action expands into 12 rows of the form { entity: { name: “ “, value: …}, feature: { name: “ “, value: …} } that must be inserted in your DocumentDB collection with the previously created stored procedure. We did this process in batches, the size of which can be configured.
private static string[] Featurize(RfmDoc doc)
{
List result = new List();
var entities = new Tuple<string, object>[] { new Tuple<string, object>(“eid”, doc.Eid), new Tuple<string, object>(“cid”, doc.Cid),
new Tuple<string, object>(“uid”, doc.Uid) };
var features = new Tuple<string, object>[] { new Tuple<string, object>(“time”, doc.Time), new Tuple<string, object>(“src_evt”, doc.SourceEvent),
new Tuple<string, object>(“cat”, doc.Cat), new Tuple<string, object>(“obj”, doc.Obj) };
foreach (var entity in entities)
{
foreach (var feature in features)
{
StringBuilder eb = new StringBuilder();
StringBuilder fb = new StringBuilder();
StringWriter eWriter = new StringWriter(eb);
StringWriter fWriter = new StringWriter(fb);
JsonSerializer s = new JsonSerializer();
s.Serialize(eWriter, entity.Item2);
string eValue = eb.ToString();
s.Serialize(fWriter, feature.Item2);
string fValue = fb.ToString();
var value = string.Format(CultureInfo.InvariantCulture, “{{\”entity\”:{{\”name\”:\”{0}\”,\”value\”:{1}}},\”feature\”:{{\”name\”:\”{2}\”,\”value\”:{3}}}}}”,
entity.Item1, eValue, feature.Item1, fValue);
result.Add(value);
}
}
return result.ToArray();
}
Step 3
Execute the stored procedure created in step 1.
The stored procedure takes as input a row of the form { entity: { name: “ ”, value: …}, feature: { name: “ ”, value: …} } and updates the relevant feature metadata to produce a document of the form { entity: { name: “”, value: “” }, feature: { name: “”, value: …}, isMetadata: true, aggregates: { “count”: …, “min”: … } }. Depending on the name of the feature in the document that is being inserted into DocumentDB, a subset of predefined aggregates is updated. For example, if the feature name of the document is “cat” (category), the count_unique_hll aggregate is employed to keep track of the unique count of categories. Alternatively, if the feature name of the document is “time”, the minimum and maximum aggregates are utilized. The following code snippet demonstrates how the distinct count and minimum aggregates are updated. See the next section for a more detailed description of the data structures that we are using to maintain these aggregates.
case AGGREGATE.count_unique_hll:
if (aggData === undefined) aggData = metaDoc.aggregates[agg] = new CountUniqueHLLData();
aggData.hll = new HyperLogLog(aggData.hll.std_error, murmurhash3_32_gc, aggData.hll.M);
let oldValue = aggData.value = aggData.hll.count();
aggData.hll.count(doc.feature.value); // add entity to hll
aggData.value = aggData.hll.count();
if (aggData.value !== oldValue && !isUpdated) isUpdated = true;
break;
case AGGREGATE.min:
if (aggData === undefined) aggData = metaDoc.aggregates[agg] = new AggregateData();
if (aggData.value === undefined) aggData.value = doc.feature.value;
else if (doc.feature.value < aggData.value) {
aggData.value = doc.feature.value;
if (!isUpdated) isUpdated = true;
}
break;
Probabilistic Data Structures
We implemented the following three probabilistic data structures in JavaScript, each of which can be updated conditionally as part of the stored procedure created in the previous section.
Hyper Log
Approximates the number of unique elements in a multiset by applying a hash function to each element in the multiset (obtaining a new multiset of uniformly distributed random numbers with the same cardinality as the original set) and calculating the maximum number of leading zeros in the binary representation of each number in the new set n. The estimated cardinality is 2^n [2].
Bloom Filter
Tests whether an element is a member of a set. While false positives are possible, false negatives are not. Rather, a bloom filter either returns maybe in the set or definitely not in the set when asked if an element is a member of a set. To add an element to a bloom filter, the element is fed into k hash functions to arrive at k array positions. The bits at each of those positions are set to 1. To test whether an element is in the set, the element is again fed to each of the k hash functions to arrive at k array positions. If any one of the bits is 0, the element is definitely not in the set [3].
Count-Min Sketch
Ingests a stream of events and counts the frequency of distinct members in the set. The sketch may be queried for the frequency of a specific event type. Similar to the bloom filter, this data structure uses some number of hash functions to map events to values – however, it uses these hash functions to keep track of event frequencies instead of whether or not the event exists in the dataset [4].
Each of the above data structures returns an estimate within a certain range of the true value, with a certain probability. These probabilities are tunable, depending on how much memory you are willing to sacrifice. The following snippet shows how to retrieve the HyperLogLog approximation for the number of unique objects for the student with eid = 1.
private static void OutputResults()
{
var client = new DocumentClient(new Uri(Endpoint), AuthKey);
Uri collectionLink = UriFactory.CreateDocumentCollectionUri(DbName, CollectionName);
string queryText = “select c.aggregates.count_unique_hll[\”value\”] from c where c.id = \”_en=eid.ev=1.fn=obj\””;
var query = client.CreateDocumentQuery(collectionLink, queryText);
Console.WriteLine(“Result: {0}”, query.ToList()[0]);
Conclusion
The range of scenarios where RFM features can have a positive impact extends far beyond churn prediction. Time and time again, a small number of RFM features have proven to be successful when used in a wide variety of machine learning competitions and customer scenarios.
Combining the power of RFM with DocumentDB’s server-side programming capabilities produces a synergistic effect. In this post, we demonstrate how to get started with event modeling and maintaining feature data with DocumentDB stored procedures. It is our hope that developers are now equipped with the tools to add functionality to our samples hosted on GitHub to maintain additional feature metadata on a case by case basis. Stay tuned for a future post that details how to integrate this type of solution with Azure Machine Learning where you can experiment with a wide variety of machine learning models on your data featurized by DocumentDB.
By Emily Lawton Software Engineer, Azure DocumentDB